Biến kho ghi chú cá nhân thành trợ lý AI thông minh chạy Offline: Không cần GPU, bảo mật tuyệt đối

Hướng dẫn chi tiết cách kết hợp Ollama, AnythingLLM và mô hình ngôn ngữ lớn để tạo hệ thống RAG cá nhân. Bạn có thể truy vấn hàng ngàn ghi chú local một cách thông minh mà không cần kết nối internet hay lo rò rỉ dữ liệu.
Nỗi khổ của việc sở hữu hàng ngàn ghi chú nhưng không thể khai thác
Nhiều người trong chúng ta sở hữu một 'kho tàng' kiến thức khổng lồ được tích lũy qua nhiều năm: từ các vault trong Obsidian, những tệp Markdown rải rác, cho đến các tài liệu nghiên cứu dang dở hay biên bản cuộc họp từ vài năm trước. Tuy nhiên, vấn đề lớn nhất không nằm ở việc lưu trữ mà là ở khâu truy xuất. Các công cụ tìm kiếm truyền thống dựa trên từ khóa đôi khi rất bất lực. Bạn có thể tìm thấy một ghi chú chứa từ 'Docker', nhưng lại không thể yêu cầu máy tính tổng hợp kiến thức từ năm tệp khác nhau để chỉ cho bạn cách triển khai container trong một môi trường bị hạn chế về tường lửa. Thực tế tại Việt Nam, nhiều chuyên gia công nghệ cũng đang đối mặt với tình trạng 'ngập lụt' thông tin nhưng khi cần lại phải lục lọi thủ công rất mất thời gian.
Một giải pháp hiển nhiên là sử dụng ChatGPT, nhưng điều này đi kèm với rủi ro bảo mật dữ liệu. Việc tải toàn bộ bí mật kinh doanh, ghi chú dự án cá nhân lên đám mây của bên thứ ba khiến nhiều người e ngại. Đó chính là lý do tác giả Yash Kiran Patil đã tìm đến giải pháp sử dụng AI cục bộ (Local AI). Hệ thống này hoạt động hoàn toàn trên máy tính của bạn, không cần GPU rời đắt đỏ, không tốn phí đăng ký hàng tháng và quan trọng nhất là dữ liệu không bao giờ rời khỏi thiết bị. Đây là một bước tiến quan trọng cho cộng đồng tự chủ dữ liệu (Self-hosting) tại Việt Nam, nơi quyền riêng tư ngày càng được coi trọng.

Cơ chế RAG: Linh hồn của trợ lý AI cá nhân
Để AI có thể hiểu và trả lời dựa trên ghi chú của bạn, kỹ thuật được sử dụng là RAG (Retrieval-Augmented Generation - Tạo lập tăng cường truy xuất). Thay vì cố gắng bắt mô hình AI học thuộc lòng hàng ngàn trang tài liệu (vốn tốn kém và bất khả thi với máy tính cá nhân), RAG hoạt động bằng cách đọc ghi chú của bạn ngay tại thời điểm bạn đặt câu hỏi. Nó sẽ quét qua kho dữ liệu, tìm ra những đoạn văn bản liên quan nhất, sau đó cung cấp chúng làm ngữ cảnh cho AI để tạo ra câu trả lời chính xác. Hãy tưởng tượng điều này giống như việc bạn đưa cho một học sinh giỏi (AI) một cuốn sách tham khảo chính là ghi chú của bạn và yêu cầu em đó tóm tắt câu trả lời.
Lựa chọn phần cứng và mô hình ngôn ngữ phù hợp

Sai lầm phổ biến của nhiều hướng dẫn trên mạng là khuyên người dùng chạy các mô hình quá lớn (như 7B parameters) trên laptop văn phòng thông thường, dẫn đến việc mất hàng phút mới nhận được một câu trả lời đơn giản. Nếu bạn chỉ sở hữu một chiếc máy tính có CPU tầm trung và khoảng 8GB-16GB RAM, 'điểm ngọt' về hiệu năng sẽ nằm ở các mô hình nhỏ gọn như Phi-3 Mini của Microsoft (3.8B) hoặc Gemma 2B từ Google. Trong các thử nghiệm thực tế trên máy 16GB RAM không GPU, Phi-3 Mini chỉ mất khoảng 5-8 giây để phản hồi, một con số rất ấn tượng và hoàn toàn chấp nhận được cho công việc hàng ngày.
Bước 1: Cài đặt Ollama làm nền tảng chạy mô hình
Ollama là công cụ mạnh mẽ và đơn giản nhất hiện nay để chạy các mô hình ngôn ngữ lớn (LLM) nội bộ. Nó hoạt động như một dịch vụ chạy ngầm và cho phép bạn tải về cũng như vận hành các mô hình chỉ với vài dòng lệnh. Để bắt đầu trên môi trường Linux, bạn chỉ cần thực hiện lệnh cài đặt qua script chính thức của họ.

curl -fsSL https://ollama.com/install.sh | shSau khi quá trình cài đặt hoàn tất, bạn cần kiểm tra lại xem dịch vụ đã hoạt động hay chưa bằng cách kiểm tra phiên bản và trạng thái của hệ thống thông qua systemd.
ollama --version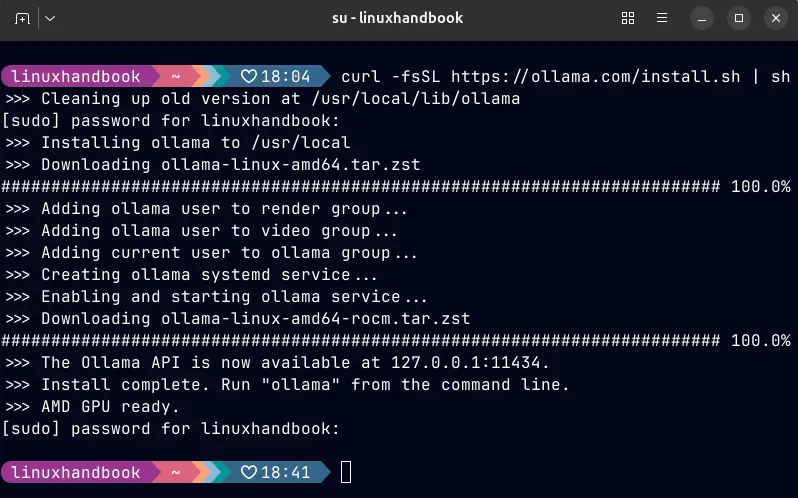
systemctl status ollamaBây giờ, hãy tải mô hình Phi-3 Mini mà chúng ta đã lựa chọn. Với dung lượng khoảng 2.3 GB, bạn sẽ mất một chút thời gian tùy thuộc vào tốc độ đường truyền internet. Nếu bạn có phần cứng mạnh hơn (trên 16GB RAM), bạn có thể cân nhắc thử nghiệm thêm mô hình Gemma 2B của Google để so sánh chất lượng câu trả lời.
ollama pull phi3:mini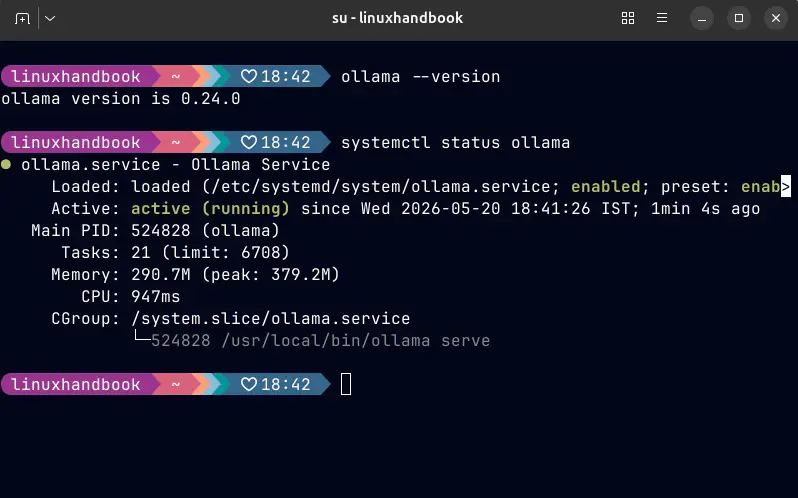
ollama pull gemma2:2bĐể chắc chắn mọi thứ đã sẵn sàng trước khi đi tiếp, hãy thử đặt một câu hỏi trực tiếp cho mô hình thông qua terminal.
ollama run phi3:mini "Explain what the ITIM subject is all about."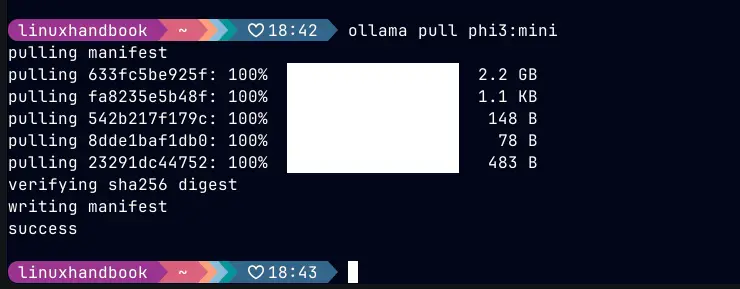
Bước 2: Thiết lập giao diện quản lý AnythingLLM qua Docker
Dù Ollama rất mạnh nhưng nó thiếu một giao diện thân thiện và khả năng quản lý tài liệu lưu loát. AnythingLLM xuất hiện để giải quyết vấn đề này. Đây là ứng dụng mã nguồn mở giúp bạn 'nhúng' (embedding) tài liệu, tạo cơ sở dữ liệu vector và trò chuyện với chúng thông qua web UI. Cách tốt nhất để cài đặt là sử dụng Docker để đảm bảo tính cô lập và dễ dàng quản lý.
docker pull mintplexlabs/anythingllm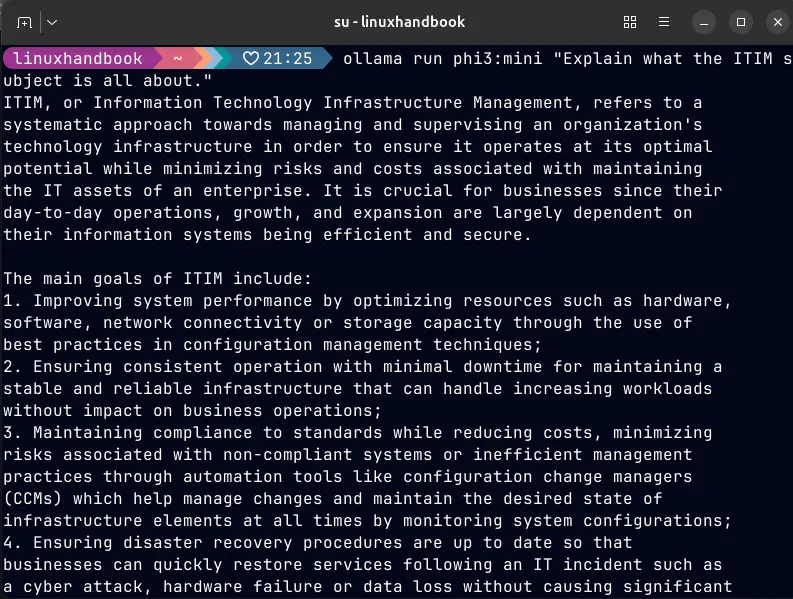
Tiếp theo, hãy tạo một thư mục để lưu trữ dữ liệu bền vững cho AnythingLLM và khởi chạy container. Lưu ý biến môi trường và việc gắn volume để dữ liệu không bị mất khi container khởi động lại.
mkdir -p ~/.anythingllmdocker run -d \
--network=host \
--cap-add SYS_ADMIN \
-v $HOME/.anythingllm:/app/server/storage \
-e STORAGE_DIR="/app/server/storage" \
--name anythingllm \
mintplexlabs/anythingllm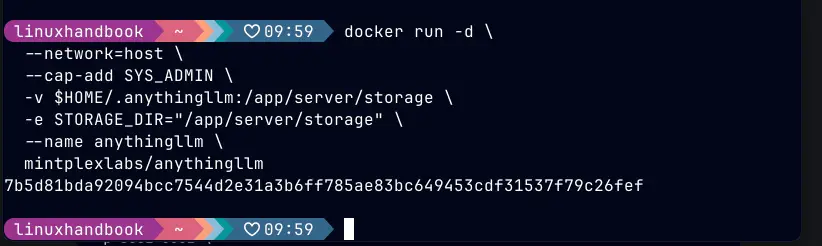
Sau khi khởi chạy, bạn có thể truy cập giao diện tại địa chỉ http://localhost:3001. Trong trình hướng dẫn thiết lập (setup wizard), hãy chọn Ollama làm nhà cung cấp LLM với URL là http://localhost:11434. Đối với mô hình Embedding (mô hình quan trọng để chuyển văn bản thành vector có thể tìm kiếm), hãy sử dụng nomic-embed-text vì nó rất nhẹ (chỉ 274MB) và tối ưu cực tốt cho tiếng Anh cũng như các tài liệu văn bản.
ollama pull nomic-embed-textBước 3: Nạp dữ liệu ghi chú và bắt đầu truy vấn

Trong AnythingLLM, bạn tạo các 'Workspace' (không gian làm việc) để phân loại kiến thức theo dự án hoặc chủ đề. Sau khi tạo Workspace mới, bạn chỉ cần kéo thả các tệp Markdown, PDF, hay thậm chí là file Word vào khu vực tải lên. Hệ thống sẽ tự động thực hiện quy trình 'chunking' (chia nhỏ văn bản) và lưu vào cơ sở dữ liệu vector LanceDB cục bộ. Nếu bạn dùng Obsidian, chỉ cần trỏ đường dẫn đến thư mục Vault của mình.
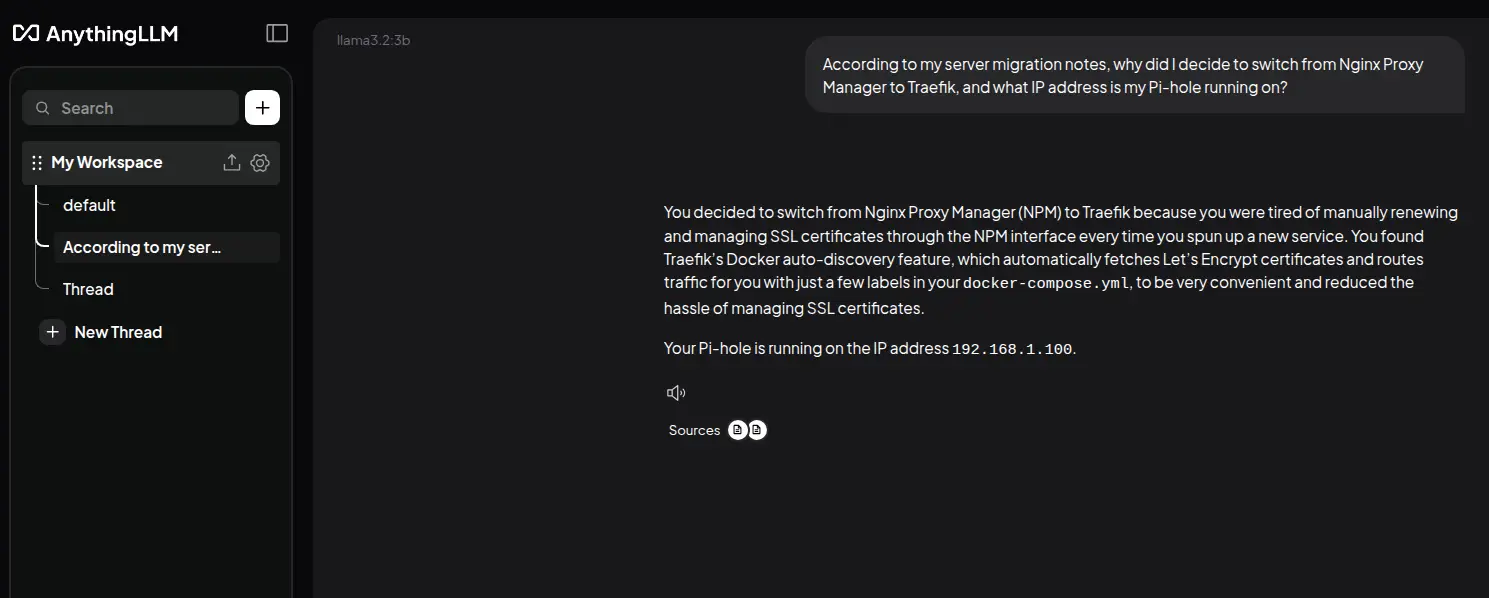
Điểm mạnh nhất của hệ thống này là khả năng trả lời các câu hỏi siêu cá nhân hóa mà không AI công cộng nào biết được. Ví dụ, bạn có thể hỏi về một quyết định chuyển đổi phần mềm trong quá khứ hoặc thông tin kỹ thuật đặc thù của hệ thống mạng tại nhà mình.
According to my server migration notes, why did I decide to switch from Nginx Proxy Manager to Traefik, and what IP address is my Pi-hole running on?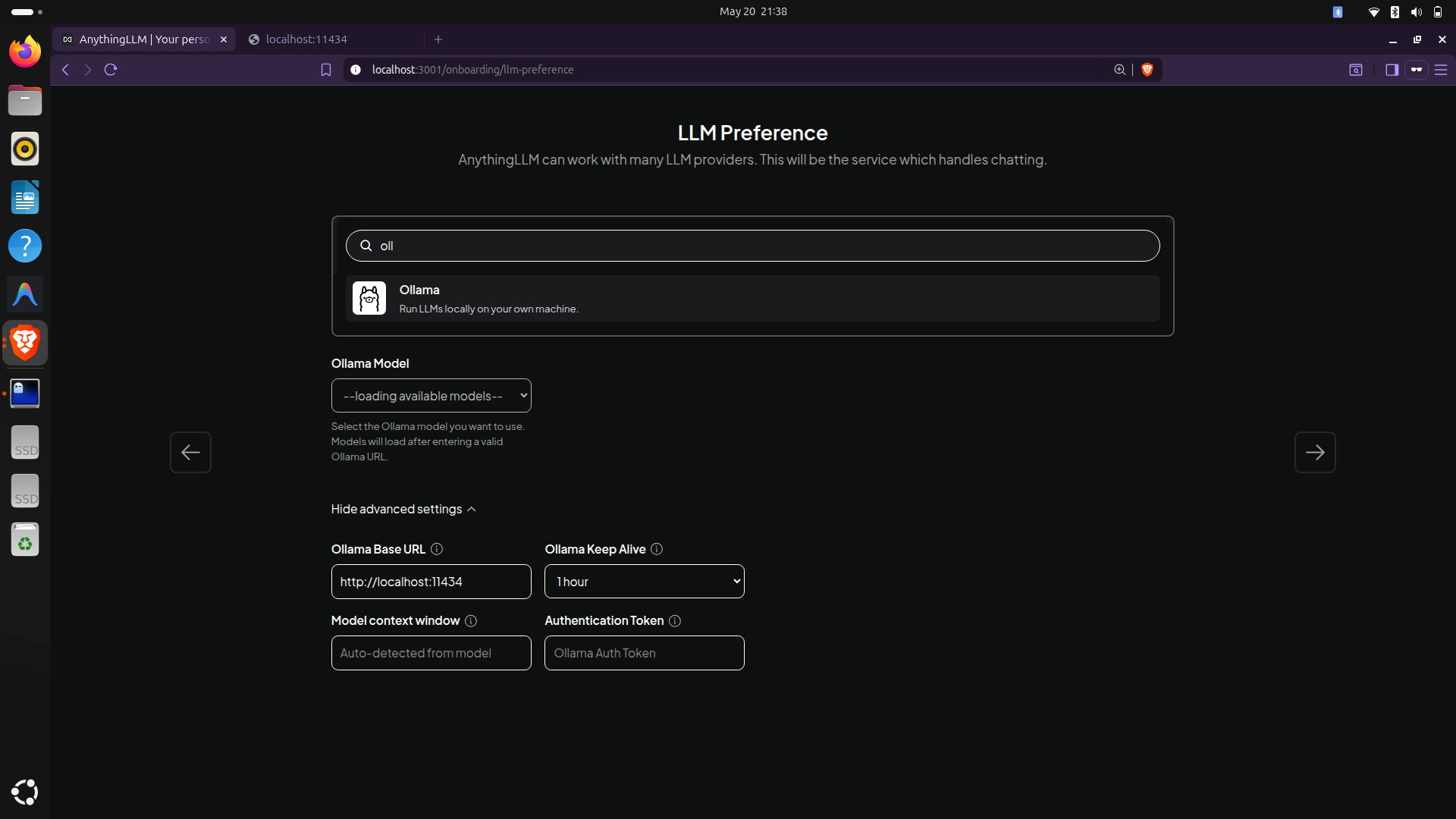
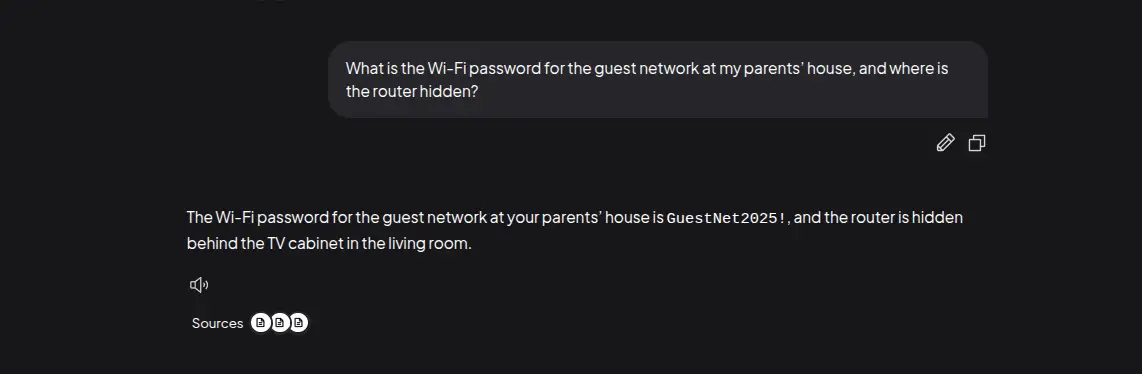
Thậm chí bạn có thể dùng nó như một kho lưu trữ mật khẩu nội bộ hoặc lịch trình gia đình một cách an toàn.
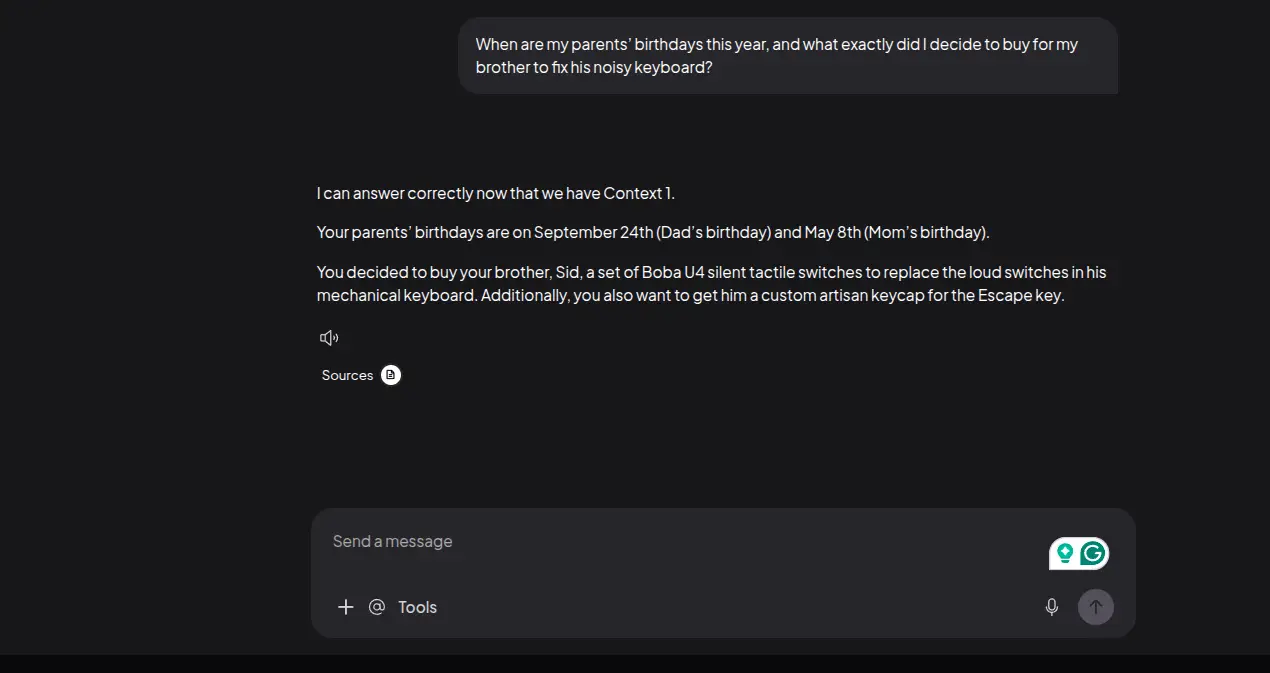
What is the Wi-Fi password for the guest network at my parents' house, and where is the router hidden?When are my parents' birthdays this year, and what exactly did I decide to buy for my brother to fix his noisy keyboard?
Duy trì hệ thống và những lưu ý thực tế
Để hệ thống luôn sẵn sàng, bạn nên cấu hình để Docker tự khởi động cùng máy tính. Ollama mặc định đã được quản lý bởi systemd nên sẽ tự chạy khi bạn bật máy. Khi có các phiên bản mô hình mới được cập nhật, việc nâng cấp cũng cực kỳ đơn giản qua lệnh pull.
docker update --restart unless-stopped anythingllm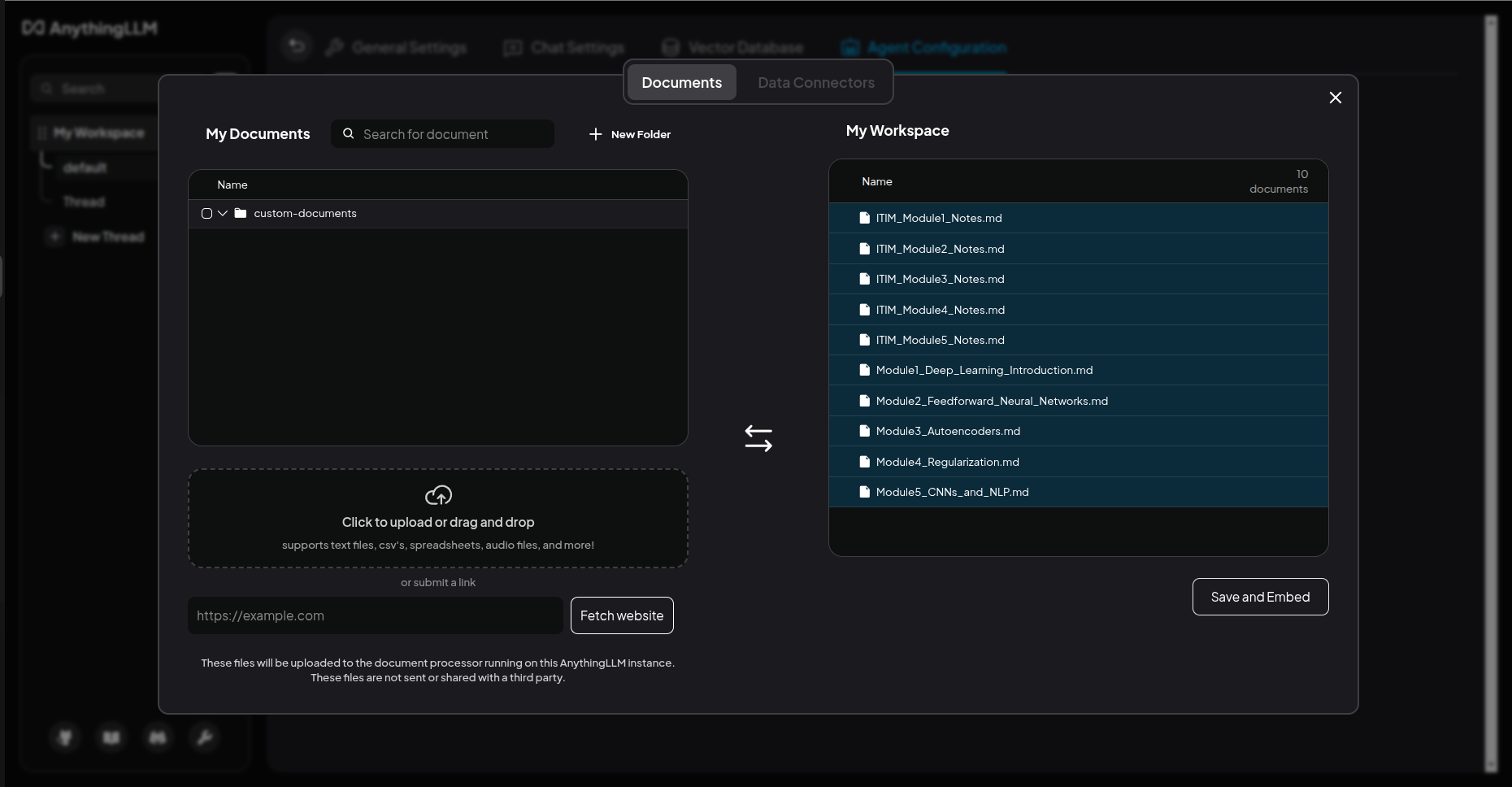
ollama pull phi3:miniSau vài tháng trải nghiệm, tác giả nhận thấy quy trình làm việc thay đổi rõ rệt. Thay vì ngồi đối chiếu thủ công 5 tệp ghi chú khác nhau để tìm một giải pháp, AI giúp tổng hợp câu trả lời kèm theo trích dẫn nguồn cụ thể chỉ trong vài giây. Tuy nhiên, cũng cần lưu ý một số hạn chế: Các tệp PDF quá dài (trên 50 trang) nên được chia nhỏ; các khối mã nguồn phức tạp đôi khi làm AI bối rối khi chia đoạn; và quan trọng nhất là hiện tượng 'ảo giác' (hallucination) vẫn có thể xảy ra nếu dữ liệu đầu vào của bạn quá mỏng. Lời khuyên cho người dùng Việt Nam là hãy luôn kiểm tra lại nguồn trích dẫn mà AnythingLLM hiển thị bên dưới câu trả lời.
Kết luận
Quan niệm AI phải là 'dịch vụ đám mây' đang dần thay đổi. Với một mô hình nhỏ chạy cục bộ, bạn có thể không giải được các bài toán lập trình siêu khó hay viết kịch bản phim, nhưng để 'điều hướng' và 'tổng hợp' kho tri thức cá nhân thì nó hoàn thành xuất sắc nhiệm vụ. Đây là một giải pháp miễn phí, mã nguồn mở và cực kỳ an toàn cho bất kỳ ai muốn nắm quyền kiểm soát dữ liệu kiến thức của chính mình.